
Introduction: Why GPU Tiering Now?
As enterprises are working on scalable AI workloads—LLMs, vision models, edge inference—there’s one universal truth: not all GPUs are equal, and not every workload needs the most expensive silicon.
In a world where NVIDIA H100s are fetching $25,000+ per unit, and AMD’s MI300X is climbing fast, GPU tiering is no longer just a cost optimization technique—it’s a strategic infrastructure model.
At Oplexa, we help organizations align GPU investments with actual workload demands. The result? Reduced TCO, improved utilization, and accelerated time-to-insight.
What is GPU Tiering?

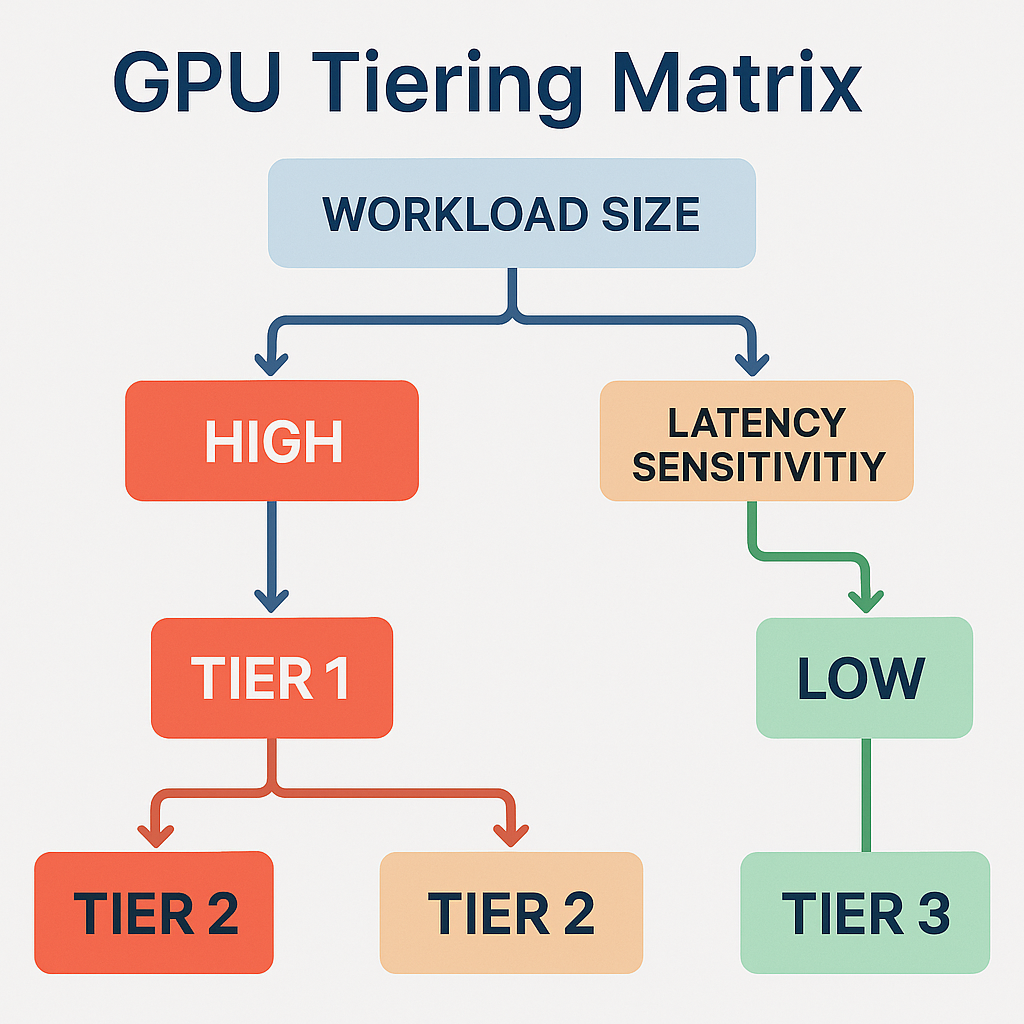
GPU tiering is the practice of categorizing and allocating different classes of GPUs—based on performance, memory, power consumption, and cost—across AI workloads to optimize efficiency and ROI.
It’s analogous to storage tiering, but applied to compute.
Typical GPU Tiers:
| Tier | Example GPUs | Best For |
| Tier 1 | NVIDIA H100, AMD MI300X | LLM training, scientific simulation |
| Tier 2 | NVIDIA A100, AMD MI250 | Fine-tuning, high-volume inference |
| Tier 3 | L4, A10G, RTX 4090 | Edge inference, classical ML, batch jobs |
Why It Matters: Avoiding the ‘One-GPU-Fits-All’ Trap
The performance-to-cost delta between tiers can be 5–10x. For example:
- A Tier 1 GPU might process a model 2x faster than a Tier 2,
but cost 4x more per hour in a cloud setting.
By assigning the right workload to the right tier, companies can:
– Avoid overprovisioning
– Extend hardware lifespan
– Control AI infrastructure energy usage
– Improve scheduling efficiency with hybrid clusters
GPU Tiering in Practice: 3 Real-World Use Cases
- Retail AI
- Tier 3 GPUs serve real-time object detection at edge (e.g. stores)
- Tier 2 GPUs train updated models weekly
- Tier 1 GPUs reserved for quarterly foundation model training
- Financial Services
- Tier 1 runs Monte Carlo simulations with GPU acceleration
- Tier 2 handles fraud detection pipelines
- Tier 3 supports model explainability tools and dashboards
- Enterprise NLP
- Tier 1 trains custom LLMs
- Tier 2 runs multi-language inference in production
- Tier 3 supports document parsing and classical NLP tasks
Oplexa’s Framework for GPU Tiering Strategy

We work with CTOs, CIOs, and CAIOs to design a tiered GPU infrastructure strategy across hybrid environments.
Our approach includes:
- Workload classification based on model size, latency sensitivity, and retrain frequency
- Cost-performance benchmarking across vendors and generations
- Deployment strategy: on-prem vs. cloud vs. colocation
- Dynamic orchestration using scheduling and model routing platforms
When Tiering Meets AI Scaling: Unlocking 30–60% Savings
GPU tiering isn’t about doing less—it’s about doing more with smarter choices.
We’ve helped clients save up to:
- $8–12M annually on cloud GPU bills
- 40% less energy through intelligent GPU pooling
- 50% faster pipeline turnaround with targeted resource assignment
Conclusion: Tiered Compute is the Future of AI Infrastructure
As the AI stack becomes more complex and specialized, so must the infrastructure behind it. GPU tiering provides a structured path to scale AI investments sustainably—without sacrificing performance.
Request our latest reports or book a consultation: