By Carter James | Oplexa Insights
April 2026 18 Min Read
In a 48-hour window this week, two of the most consequential AI model releases of 2026 landed simultaneously: OpenAI’s GPT-5.5 on April 23 and DeepSeek’s V4 on April 24. The gap between them — in benchmarks — is narrower than most enterprises expected. The price gap is 7x. That combination is the most important inference margin signal of the year.
This is Oplexa’s complete analysis of DeepSeek V4 vs GPT-5.5 — the technical architecture, full benchmark comparison, real pricing math, enterprise deployment implications, and what the DeepSeek V4 vs GPT-5.5 price and performance gap means for the AI inference market through 2028. Every enterprise AI team evaluating DeepSeek V4 vs GPT-5.5 this week needs this breakdown before making model decisions.
Why the DeepSeek V4 vs GPT-5.5 Battle Is the Most Important AI Story of April 2026
The DeepSeek V4 vs GPT-5.5 comparison matters far beyond the benchmark leaderboard. What launched this week is not just two new AI models — it is the clearest signal yet that the AI inference market is structurally bifurcating into two economic tiers: a closed-source, premium-priced tier where OpenAI, Anthropic, and Google compete on marginal benchmark gains, and an open-source, aggressively-priced tier where Chinese AI labs — led by DeepSeek — compress inference margins to near zero.
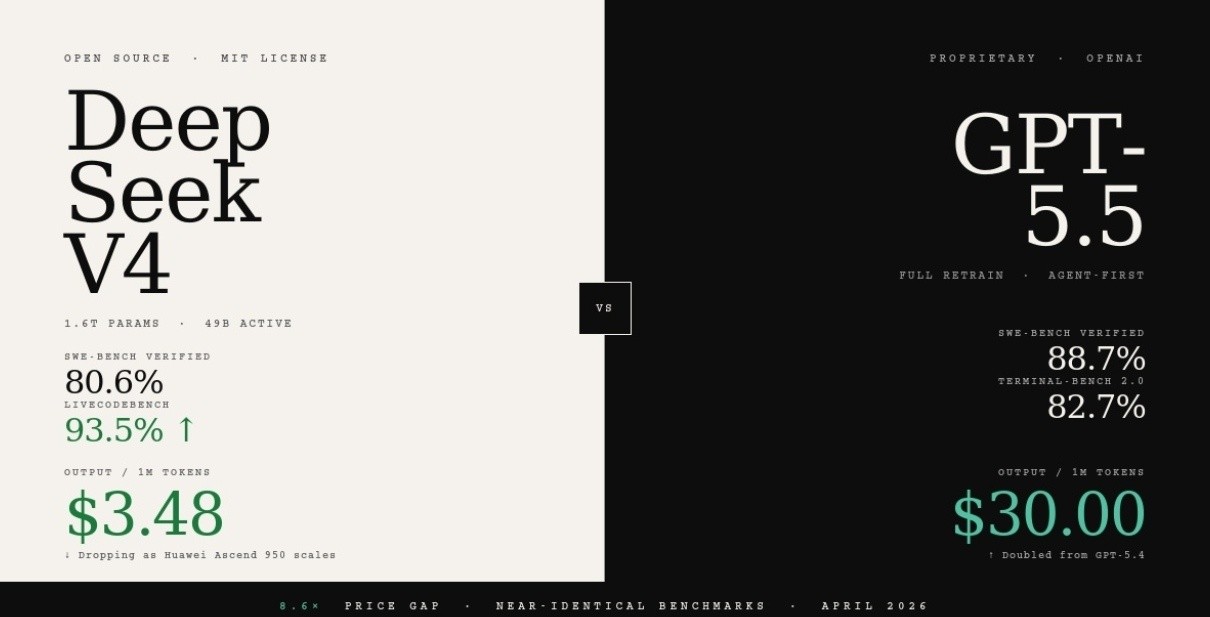
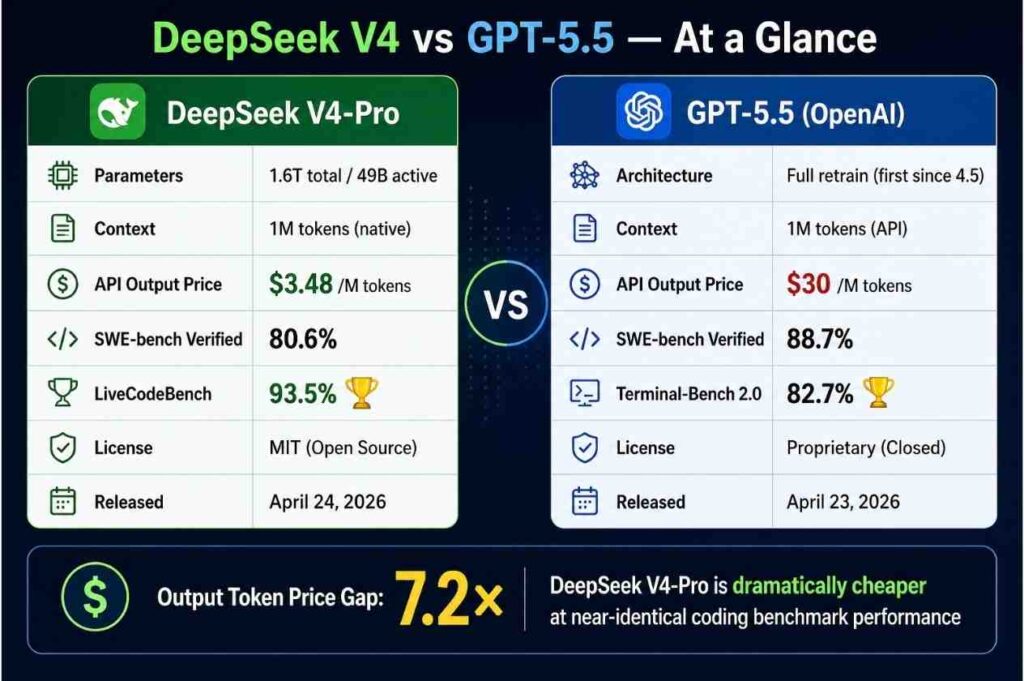
The timing is not coincidental. GPT-5.5 launched on April 23, 2026, just one week after Anthropic released Claude Opus 4.7 and reclaimed the coding benchmark crown. The very next day, DeepSeek dropped V4-Pro and V4-Flash on Hugging Face — a 1.6 trillion parameter open-source model that scores 80.6% on SWE-bench Verified, within 0.2 points of Claude Opus 4.6, at $3.48 per million output tokens versus Claude’s $25.
For enterprise AI teams evaluating DeepSeek V4 vs GPT-5.5, the question is no longer “which model is smarter?” The question is: “at what benchmark gap does a 7x price difference stop mattering?” That calculation is now the central decision in enterprise AI procurement.
📊 Oplexa Report: The Inference War: Margin Compression & AI Market Dynamics 2026–2028 — Full analysis of inference pricing trajectories, open vs closed source economics, DeepSeek vs OpenAI market share projections, and the $480B inference market through 2028. $1,499 →
DeepSeek V4 Architecture: What Makes It Technically Significant
The DeepSeek V4 release is technically distinct from its predecessors in ways that go beyond parameter counts. Understanding the architecture is essential for evaluating the DeepSeek V4 vs GPT-5.5 tradeoff, because DeepSeek’s efficiency gains are structural — not just the result of training on more data.
Mixture-of-Experts Architecture — 1.6T Parameters, Only 49B Active
DeepSeek V4-Pro has 1.6 trillion total parameters, with 49 billion activated per token, and is pre-trained on 33 trillion tokens. V4-Flash is the efficiency variant at 284 billion total parameters with 13 billion active. The MoE architecture is why DeepSeek can offer frontier-competitive performance at dramatically lower inference costs — you are only paying to activate a fraction of the model per request.
Hybrid Attention — The Efficiency Breakthrough
DeepSeek V4’s most consequential innovation is its hybrid attention mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). At a 1 M-token context, V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek V3.2. That 10x KV cache reduction is what makes 1M-token context economically viable at DeepSeek’s price point — competitors offering 1M context on standard attention architectures pay 10x more compute to deliver it.
Trained Partly on Huawei Ascend Chips
The chip story around DeepSeek V4 is one of the most consequential elements of the DeepSeek V4 vs GPT-5.5 comparison. Huawei confirmed that its latest AI computing cluster, powered by its Ascend AI processors, can support DeepSeek’s V4 model. DeepSeek expects to lower V4-Pro prices later in the year as Huawei scales up production of its new Ascend 950 AI processors. This means the already-aggressive pricing on DeepSeek V4 has a further downside trajectory — as Chinese domestic chip production scales, DeepSeek’s inference costs will fall further while US labs continue paying NVIDIA GPU pricing.

GPT-5.5 Architecture: What OpenAI Built and Why It Doubled the Price
The GPT-5.5 side of the DeepSeek V4 vs GPT-5.5 comparison is equally significant. GPT-5.5 is the first fully retrained base model since GPT-4.5 — every GPT-5.x release between them was a post-training iteration on top of the same base. GPT-5.5 is not. The architecture, pretraining corpus, and agent-oriented objectives have all been reworked. OpenAI describes it as a system that takes a sequence of actions, uses tools, checks its own work, and keeps going until a task is finished — without needing a human to re-prompt.
The pricing story is stark in the DeepSeek V4 vs GPT-5.5 comparison. OpenAI doubled the per-token price on the GPT-5 line with GPT-5.5. Input goes from $2.50 to $5.00 per million tokens. Output goes from $15.00 to $30.00 per million. OpenAI’s justification — that GPT-5.5 uses ~40% fewer tokens to complete the same tasks — makes the net cost increase closer to 20% in practice. But at $30/M output tokens versus DeepSeek V4-Pro’s $3.48/M, the sticker gap in the DeepSeek V4 vs GPT-5.5 debate remains 8.6x on output pricing.
GPT-5.5 Hallucination Problem — The Hidden Cost
One critical detail in the DeepSeek V4 vs GPT-5.5 evaluation that most benchmark comparisons underweight: on AA-Omniscience, GPT-5.5 posts the highest-ever accuracy at 57%, but carries an 86% hallucination rate — it answers confidently even when it’s wrong. Claude Opus 4.7 sits at 36%; Gemini 3.1 Pro Preview at 50%. For knowledge-intensive enterprise deployments in legal, finance, or healthcare, that hallucination rate gap has direct liability implications that no benchmark score can offset.
The Real Cost Math: DeepSeek V4 vs GPT-5.5 Enterprise Workload Analysis
Abstract benchmark comparisons and per-token pricing do not tell enterprises what they need to know about DeepSeek V4 vs GPT-5.5. Real cost analysis requires workload modeling. Here is what the numbers look like at enterprise AI scale.
DeepSeek V4 vs GPT-5.5 — Scenario A: High-Volume AI Coding Agent (10M output tokens/month)
| Model | Monthly API Cost | SWE-bench Score | Cost per 1% Benchmark |
|---|---|---|---|
| DeepSeek V4-Pro | $34.80 | 80.6% | $0.43 |
| GPT-5.5 Standard | $300.00 | 88.7% | $3.38 |
| Claude Opus 4.7 | $250.00 | ~87.6% | $2.85 |
| DeepSeek V4-Flash | $2.80 | ~72% | $0.04 |
At 10M output tokens per month, DeepSeek V4-Pro costs $34.80 versus GPT-5.5’s $300. The SWE-bench gap is 8.1 percentage points. For most enterprise coding agent workloads — where the limiting factor is the quality of task specification, not the frontier benchmark score — that 8-point gap does not justify an 8.6x cost premium. This is the core DeepSeek V4 vs GPT-5.5 economics argument.
DeepSeek V4 vs GPT-5.5 — Scenario B: Enterprise Agentic Workflow (100M output tokens/month)
| Model | Monthly API Cost | Annual Cost | Annual Saving vs GPT-5.5 |
|---|---|---|---|
| DeepSeek V4-Pro | $348 | $4,176 | $31,824 saved |
| DeepSeek V4-Flash | $28 | $336 | $35,664 saved |
| GPT-5.5 Standard | $3,000 | $36,000 | — |
| Claude Opus 4.7 | $2,500 | $30,000 | $6,000 saved |
At 100M tokens/month — a realistic scale for a mid-size enterprise running AI agents across internal workflows — the annual cost difference between DeepSeek V4 and GPT-5.5 is $31,824. That is a meaningful line item for any technology budget. For large enterprises running billions of tokens monthly, the DeepSeek V4 vs GPT-5.5 cost delta compounds into seven-figure annual savings.
What This Means for the AI Inference War — The Oplexa View
The DeepSeek V4 vs GPT-5.5 simultaneous release is not just a product comparison. It is a structural signal about where the AI inference market is heading. Three implications stand out.
DeepSeek V4 vs GPT-5.5 Signal #1: Inference Margin Compression Is Accelerating
OpenAI raised prices to $30/M output tokens with GPT-5.5. DeepSeek released a near-frontier competitor at $3.48/M the same week. This gap cannot persist indefinitely — either OpenAI’s pricing power erodes as enterprise procurement cycles shift toward open-source alternatives, or DeepSeek’s benchmark quality improves to the point where the 8-point SWE-bench gap disappears entirely. Either outcome means inference margins for closed-source labs compress further through 2026–2028. According to Counterpoint Research’s Wei Sun, DeepSeek V4’s benchmark profile suggests it could offer “excellent agent capability at significantly lower cost.”
DeepSeek V4 vs GPT-5.5 Signal #2: Open Source Is Now a Genuine Enterprise Option
Stanford’s AI Index 2026 concludes that Chinese companies have “effectively closed” the AI performance gap with their US rivals. The DeepSeek V4 vs GPT-5.5 comparison validates that assessment quantitatively. An open-source model scoring 80.6% on SWE-bench Verified — within 8 points of the best closed-source model in the world — at MIT license with full self-hosting rights, is not a compromise choice. For enterprises with data sovereignty requirements, regulated industries, or simply cost pressure, DeepSeek V4 is now a credible primary deployment option.
3. The NVIDIA GPU Cost Advantage Is Being Weaponized Against US AI Labs
The most underappreciated dimension of DeepSeek V4 vs GPT-5.5 is the hardware story. DeepSeek expects to lower V4-Pro prices later in the year as Huawei scales up production of its Ascend 950 AI processors. OpenAI, Anthropic, and Google are all paying NVIDIA GPU inference costs that do not have the same downward trajectory. DeepSeek’s inference cost curve is going down. US closed-source labs’ cost curves are flat to rising. The DeepSeek V4 vs GPT-5.5 price gap, already 8.6x, will likely widen through 2026.
DeepSeek V4 vs GPT-5.5 — Security, Sovereignty & Regulatory Risk
No serious enterprise analysis of DeepSeek V4 vs GPT-5.5 is complete without the regulatory and security dimension. The DeepSeek V4 story is not just a technical and pricing story — it is a geopolitical one.
DeepSeek V4 vs GPT-5.5 — The DeepSeek Regulatory Risk
Multiple US states, Australia, Taiwan, South Korea, Denmark and Italy introduced bans or other restrictions on DeepSeek’s R1 model shortly after its release, citing privacy and national security concerns. While V4 is a new model, enterprises in regulated industries or government-adjacent sectors must evaluate DeepSeek V4 against their data residency requirements and any applicable federal guidance before deployment.
The open-source nature of DeepSeek V4 actually mitigates some of the most serious concerns: enterprises can run the model entirely on their own infrastructure, with no data leaving their perimeter. A self-hosted DeepSeek V4 deployment has no data transmission to Chinese servers — the risk profile is fundamentally different from using the API.
DeepSeek V4 vs GPT-5.5 — The GPT-5.5 Pricing and Lock-in Risk
The risk on the GPT-5.5 side of the DeepSeek V4 vs GPT-5.5 comparison is different: vendor lock-in and pricing volatility. OpenAI’s six-week release cadence — GPT-5.4 on March 5, GPT-5.5 on April 23 — is not primarily about winning benchmarks. OpenAI is releasing at this pace to establish category lock-in before enterprise procurement cycles close. Enterprises that build deep GPT-5.5 integrations today face the same re-integration costs at GPT-5.6 or GPT-6 — and OpenAI has demonstrated it will price each generation upgrade upward.
Conclusion
The DeepSeek V4 vs GPT-5.5 head-to-head comparison that landed this week is the clearest statement yet of where AI inference economics are heading. GPT-5.5 is the best benchmark score money can buy — at $30/M output tokens, doubling GPT-5.4’s price with a 6-week release cycle designed to lock enterprises into the OpenAI ecosystem. DeepSeek V4 is the answer to that pricing power — near-frontier benchmarks, 7x lower cost, open-source weights, and a pricing trajectory that goes down as Huawei Ascend production scales.
The DeepSeek V4 vs GPT-5.5 gap will not stay static. DeepSeek’s technical report explicitly flags a 3–6 month benchmark lag behind the frontier — meaning V5 is already in training on Huawei chips, and the gap to GPT-5.5 will narrow further. For enterprises making AI model procurement decisions today, the relevant question is not “which model wins the benchmark today?” It is “which side of the DeepSeek V4 vs GPT-5.5 divide will your AI cost structure sit on through 2028?”
The DeepSeek V4 vs GPT-5.5 inference war is not a future event. It launched this week. The DeepSeek V4 vs GPT-5.5 pricing gap will define enterprise AI economics through 2028.
📊 Oplexa Report: The Inference War: Margin Compression & AI Market Dynamics 2026–2028 — Full model-by-model pricing trajectory analysis, open vs closed source market share projections, enterprise AI cost modeling, DeepSeek’s competitive roadmap vs OpenAI and Anthropic, and the $480B inference market investment thesis. $1,499 →
Frequently Asked Questions
What is the main difference between DeepSeek V4 and GPT-5.5?
The main difference between DeepSeek V4 and GPT-5.5 is price versus benchmark performance. GPT-5.5 scores higher on most benchmarks — particularly Terminal-Bench 2.0 (82.7%), SWE-bench Verified (88.7%), and the AA Intelligence Index (60). DeepSeek V4-Pro scores 80.6% on SWE-bench Verified and 93.5% on LiveCodeBench — winning on competitive coding. The critical gap is pricing: GPT-5.5 costs $30 per million output tokens versus DeepSeek V4-Pro at $3.48 — a 8.6x difference. DeepSeek V4 is also open-source under MIT license, while GPT-5.5 is proprietary.
Is DeepSeek V4 better than GPT-5.5?
DeepSeek V4 is not better than GPT-5.5 on most benchmarks — GPT-5.5 leads on SWE-bench Verified, Terminal-Bench 2.0, and the overall AI Intelligence Index. However, DeepSeek V4-Pro beats GPT-5.5 on LiveCodeBench (93.5% vs ~82%) and delivers near-frontier performance at 7-8x lower cost. For high-volume inference workloads where cost is primary, DeepSeek V4 delivers better value. For correctness-critical or agentic terminal tasks, GPT-5.5 is the stronger performer.
What is DeepSeek V4-Pro’s pricing vs GPT-5.5?
DeepSeek V4-Pro costs $1.74 per million input tokens and $3.48 per million output tokens. GPT-5.5 costs $5.00 per million input tokens and $30.00 per million output tokens — making GPT-5.5 approximately 8.6x more expensive on output tokens. DeepSeek V4-Flash is even cheaper at $0.14 input / $0.28 output. At 100M output tokens per month, DeepSeek V4-Pro saves approximately $31,824 per year compared to GPT-5.5.
Can enterprises use DeepSeek V4 safely?
Enterprises can use DeepSeek V4 safely with the right deployment approach. The primary risk of DeepSeek V4 is data sovereignty — using the DeepSeek API sends data to servers outside US jurisdiction. However, DeepSeek V4 is open-source under the MIT license, meaning enterprises can self-host the model entirely on their own infrastructure with no data leaving their environment. Regulated industries and US government contractors should evaluate DeepSeek V4 against applicable federal guidance and consider self-hosted deployment rather than API access.
What is GPT-5.5’s hallucination rate?
GPT-5.5 has an 86% hallucination rate on AA-Omniscience — the highest of any major frontier model currently in production. While GPT-5.5 scores 57% accuracy on that benchmark (the highest ever), it confidently asserts wrong answers 86% of the time when it does not know. Claude Opus 4.7 has a 36% hallucination rate and Gemini 3.1 Pro Preview 50%. For enterprise deployments in legal, medical, financial, or compliance contexts in the DeepSeek V4 vs GPT-5.5 decision, this hallucination gap is a material risk factor.
When was DeepSeek V4 released?
DeepSeek V4 was released on April 24, 2026 as a preview version on Hugging Face, with API access live at api-docs.deepseek.com and chat interface available at chat.deepseek.com. The release includes two models: DeepSeek-V4-Pro (1.6 trillion parameters, 49B active) and DeepSeek-V4-Flash (284 billion parameters, 13B active). Both are under MIT license and support 1 million token context natively. The release came one day after OpenAI’s GPT-5.5 launch on April 23, 2026.
Will DeepSeek V4 get cheaper over time?
Yes — DeepSeek V4 pricing is expected to fall further through 2026. DeepSeek has stated it expects to lower V4-Pro prices as Huawei scales up production of its Ascend 950 AI processors, which were used in training V4. As Chinese domestic AI chip production expands, DeepSeek’s inference compute costs fall — and historically the lab has passed those savings to users. The already 7x price gap between DeepSeek V4-Pro and GPT-5.5 is likely to widen further through 2026.
Related Oplexa Coverage:
- AI Inference Cost Crisis 2026: Why Your AI Bill Is Exploding — The demand-side context driving the DeepSeek V4 vs GPT-5.5 cost war
- Custom ASIC Market 2026: Why Hyperscalers Are Ditching NVIDIA — Huawei Ascend’s role in enabling DeepSeek V4’s pricing
- AI Data Center Power Crisis 2026: Why $660B Capex Still Isn’t Enough — Infrastructure context for running models at scale
- GTC 2026 Wrap-Up: NVIDIA’s Answer to the Inference War — How NVIDIA Vera Rubin positions against this pricing pressure
📊 Oplexa Report: The Inference War: Margin Compression & AI Market Dynamics 2026–2028 — $1,499
Full inference pricing trajectory analysis, open vs closed source market share projections, DeepSeek competitive roadmap, enterprise AI cost modeling, and the $480B inference market investment thesis through 2028.
📊 Oplexa Report: AI Factory Economics: Cost per Token & $480B Market 2026 — $2,499
Granular cost-per-token modelling across all major models including DeepSeek V4 and GPT-5.5, AI factory deployment economics, training vs inference cost breakdown, and enterprise ROI framework 2026–2030.