
By Carter James | Oplexa Insights
Mar 2026 | 18 Min Read
NVIDIA built a $4.6 trillion empire selling one product: the world’s most powerful AI chip. But the companies that made Jensen Huang a legend are now building their own silicon — and the Custom ASIC market 2026 is the weapon they are using to do it.
Google does not buy NVIDIA GPUs to run Gemini. Amazon does not pay NVIDIA margins to train its AI models. Meta is not using general-purpose accelerators to serve 3 billion users daily. They are all running custom Application-Specific Integrated Circuits — chips designed from scratch for one purpose, executing at maximum efficiency, at a fraction of the power cost.
This shift is not a threat on the horizon. It is already happening — and the data from 2026 makes the trajectory undeniable. Custom ASIC shipments are projected to triple by 2027 compared to 2024 levels. By 2028, ASIC shipments will surpass GPU shipments for the first time in history. And the market enabling all of this — the custom AI accelerator ecosystem — is on track to exceed $600 billion by 2033.
What Is a Custom ASIC and Why Do Hyperscalers Want One?
An Application-Specific Integrated Circuit is a chip designed to do exactly one thing — and do it better than any general-purpose chip can. Unlike NVIDIA’s GPUs, which are engineered to handle any AI workload thrown at them, a custom ASIC is purpose-built for a specific model architecture, a specific inference pattern, or a specific training topology.
The trade-off is obvious: flexibility for efficiency. A GPU can run any model. A custom ASIC runs one class of models at 3-5x better performance per watt. For a startup still experimenting with architectures, GPUs are the right choice. For a hyperscaler running 10 billion inference requests daily on the same recommendation model, the economics of a custom ASIC are transformative.
The custom ASIC market in 2026 is no longer about cost savings on the margin. It is about structural competitive advantage. The hyperscaler that controls its own silicon controls its own performance roadmap, its own cost structure, and its own supply chain. These are three things that no amount of NVIDIA procurement can deliver.
🔗 Read also: Broadcom’s $100B Bet: The AI Chip War That Will Define 2027
The Four Hyperscalers and Their Custom Silicon Strategy
Google — The Longest Custom ASIC Track Record
Google deployed its first Tensor Processing Unit internally in 2015 — a full two years before NVIDIA’s Volta architecture brought tensor cores to GPUs. Google’s sixth-generation TPU, Trillium, is now in production. Its seventh-generation program involves dual-sourcing: Broadcom builds the high-performance TPU v8AX Sunfish for training workloads, while MediaTek has secured the design partnership for the inference-focused TPU v8x Zebrafish.
This dual-sourcing strategy is one of the most significant competitive developments in the custom ASIC market. It signals that Google is deliberately introducing competition between its ASIC design partners — using MediaTek’s cost-effective positioning to pressure Broadcom’s premium pricing even while maintaining Broadcom for the most demanding training workloads.
Meta — MTIA and the 5-Gigawatt Ambition
Meta revealed four new custom chips in March 2026 as part of its MTIA family. The MTIA 400 custom accelerator has completed testing and is entering production deployment in Meta’s data centers. Crucially, Meta’s next-generation MTIA chips will include significantly more High Bandwidth Memory (HBM) to power generative AI inference tasks — confirming that the custom ASIC and AI memory semiconductor markets are deeply intertwined.
Meta Vice President of Engineering Yee Jiun Song told CNBC that custom silicon provides greater price-per-performance efficiency and supply diversity. By designing chips in-house and manufacturing at TSMC, Meta insulates itself from NVIDIA margin cycles while maintaining access to the same advanced fabrication nodes.
Amazon — Trainium 3 and the AWS Cost Imperative
Amazon’s Trainium 3 chip is ramping production starting in Q2 2026, following the prior Trainium 2 and 2.5 generations. AWS’s motivation is clear: every AI workload running on Trainium instead of a third-party GPU keeps more margin inside Amazon. GPU-based systems still account for approximately 60% of AWS’s AI server build-out in 2026 — but the Trainium ramp is accelerating, and Marvell Technology has secured key design partnership wins with Amazon, positioning itself as Broadcom’s most credible competitor.
Microsoft — Maia and the Azure Pivot
Microsoft’s Maia 100 custom accelerator is deployed across Azure data centers, and Microsoft is confirmed as one of the early adopters of NVIDIA’s Vera Rubin NVL72 platform simultaneously. This dual-track strategy — deploying both custom ASICs and NVIDIA GPUs — is the most commercially pragmatic approach: custom silicon for predictable, high-volume inference workloads, NVIDIA GPUs for flexible training and experimentation. Broadcom is Microsoft’s primary ASIC design partner for the Maia program.
Hyperscaler Custom ASIC Comparison — 2026
| Company | Custom Chip | Purpose | Design Partner | Status (2026) |
| TPU v7 + v8 (Trillium) | Training + Inference | Broadcom + MediaTek | ✅ In Production | |
| Meta | MTIA 400 | Internal inference | TSMC (self-designed) | ✅ Entering Deploy |
| Amazon | Trainium 3 | Training + Inference | Marvell + internal | 🔜 Ramping Q2 2026 |
| Microsoft | Maia 100 | Azure inference | Broadcom | ✅ In Production |
| OpenAI | Titan (in dev) | Training frontier | Broadcom | 📋 Dev Phase |
Broadcom’s 60% Market Share — The Real Winner of the ASIC Boom
The story of the custom ASIC market is not just about which hyperscaler is moving fastest. It is about which semiconductor company sits at the center of all of them. The answer, by a commanding margin, is Broadcom.
Broadcom is the design partner behind Google’s TPU, Meta’s MTIA, Microsoft’s Maia, and — confirmed in early 2026 — OpenAI and Anthropic’s Titan accelerator program. Its 60% projected market share in AI server compute ASICs by 2027 is not a projection about Broadcom winning new customers. It is a reflection of partnerships already in production.
In February 2026, Broadcom announced the first 2nm custom compute System-on-a-Chip, using its 3.5D packaging technology to stack memory and compute at unprecedented density. This is the most advanced custom ASIC packaging capability in commercial production — and it gives Broadcom’s hyperscaler partners access to performance levels that even NVIDIA’s Vera Rubin cannot match for specific workloads.
Broadcom’s networking silicon is an equally important part of the equation. Its Tomahawk 5 switch ASIC handles 51.2 Terabits per second of data movement — the infrastructure backbone that connects thousands of custom ASICs in a training cluster. Without Broadcom’s networking silicon, hyperscalers cannot operate custom ASICs at scale.
| 📌 The Broadcom-NVIDIA Relationship Is Not Zero-Sum
Broadcom dominates custom ASIC design. NVIDIA dominates flexible GPU compute. Many hyperscalers deploy both simultaneously — NVIDIA GPUs for experimentation and general workloads, custom ASICs for their highest-volume, most predictable inference tasks. The custom ASIC boom does not eliminate NVIDIA’s market. It absorbs the marginal GPU demand that would otherwise go to NVIDIA at the hyperscaler tier. |
| 📊 Oplexa Research Report
Custom ASIC Projects Market 2025–2035 Execution models, customer-supplier dynamics, Broadcom vs Marvell competitive analysis & 10-year market forecast |
$999 |
ASIC vs GPU: The Economics That Drive the Shift
Custom ASIC vs NVIDIA GPU — Economics at Hyperscale
| Dimension | NVIDIA GPU (H100/Vera Rubin) | Custom ASIC (e.g., Google TPU) |
| Unit Cost | $25,000 – $40,000 per chip | Lower at scale — amortised over volume |
| Power Efficiency (task-specific) | Moderate — general-purpose overhead | 3-5x better for target workload |
| Performance (specific model) | Good across all workloads | Up to 5x better for target task |
| Supply Chain Control | Entirely dependent on NVIDIA | Controlled by hyperscaler + TSMC |
| Software Lock-in | CUDA — strongest moat in tech | Custom software stack — self-controlled |
| Development Time | None — buy immediately | 2-4 years minimum |
| Break-even Point | Immediate | 18-24 months at hyperscale volume |
| Best For | R&D, diverse workloads, fast iteration | Fixed, high-volume, production workloads |
The table above explains the structural logic of the custom ASIC shift. For a company like Google running 10 billion search ranking inferences daily on the same model architecture, the 18-24 month break-even point on custom silicon investment arrives quickly. The ongoing savings — in both cost and power — then compound annually for the lifetime of the chip generation.
| 📊 Oplexa Research Report
AI Chip Market Analysis & Forecast 2025–2035 Full ASIC vs GPU market sizing, vendor brestat calloutsakdown, Broadcom & Marvell competitive landscape |
$299 |
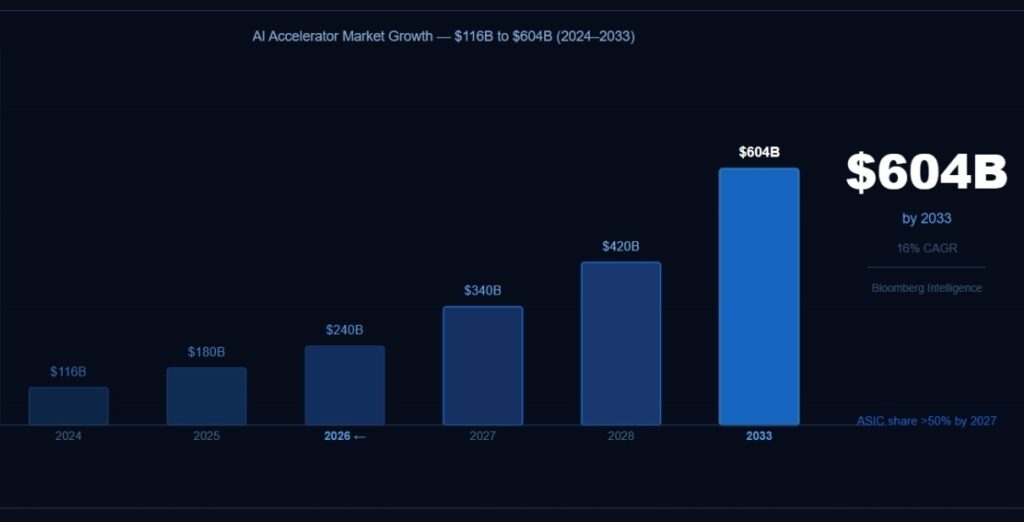
The Market Forecast: From $116B to $604B by 2033
AI Accelerator Market — Custom ASIC Growth Forecast 2024–2033
| Year | Total AI Accel. Market | ASIC Share | Key Driver |
| 2024 | $116B | ~25% | Blackwell launch, TPU v6 ramp |
| 2025 | $180B | ~32% | Trainium 2, MTIA 2nd gen |
| 2026 | $240B | ~40% | Trainium 3, MTIA 400, Maia expansion |
| 2027 | $340B | >50% | ASIC surpasses GPU shipments |
| 2028 | $420B | ~55% | 15M+ ASIC units shipped |
| 2033 | $604B | ~60%+ | Sovereign AI + enterprise ASIC programs |
The $604 billion projection from Bloomberg Intelligence represents a 16% compound annual growth rate from the $116 billion 2024 baseline. What makes this forecast credible is the existing committed capital: hyperscalers and Tier 2 cloud providers are projected to invest more than $3.5 trillion in AI-related capital expenditure through 2030. A significant portion of this capital is flowing toward custom ASIC development, not GPU procurement.
| 📊 Oplexa Research Report
AI Infrastructure Strategy 2026–2035: Capital & Compute ASIC investment strategy, semiconductor capital expenditure analysis & AI infrastructure build-out forecast |
$999 |
Key Risks: Why the Custom ASIC Shift Is Not Guaranteed
| ⚠️ CUDA Software Moat
NVIDIA’s CUDA platform is the most deeply embedded software ecosystem in AI. Every researcher, every startup, and every university AI lab writes in CUDA. Custom ASIC deployments require hyperscalers to rebuild their entire software stack from scratch — a process that takes years and costs hundreds of millions of dollars in engineering time. This is why even hyperscalers with mature ASIC programs still run significant GPU workloads alongside them. |
| ⚠️ Yield and Execution Risk at Advanced Nodes
Custom ASICs at 3nm and 2nm node sizes are extraordinarily complex. Any yield issue — where a high percentage of chips fail testing — can cause production delays that put hyperscaler roadmaps months behind schedule. Google’s dual-sourcing strategy with MediaTek is partially a hedge against exactly this risk: if one design partner encounters yield problems, production can shift to the other. |
| ⚠️ TSMC Capacity Constraints
Both custom ASICs and NVIDIA GPUs are manufactured at TSMC’s advanced nodes. As demand for both surges simultaneously, TSMC’s 3nm and 2nm capacity becomes the bottleneck for the entire AI hardware ecosystem. Hyperscalers competing with NVIDIA for TSMC capacity must plan production commitments years in advance — limiting flexibility if their AI roadmaps shift unexpectedly. |
| ⚠️ Marvell’s Competitive Pressure on Broadcom
Marvell Technology has secured Amazon and Microsoft ASIC design wins, positioning itself as the credible alternative to Broadcom. If Marvell accelerates its technology roadmap and captures additional hyperscaler programs, Broadcom’s 60% projected market share could compress — and with it, the economics of custom ASIC design partnerships that underpin Broadcom’s $100B+ AI revenue forecast. |
| 📊 Oplexa Research Report
Global Semiconductor Supply Chain Risk & Forecast 2025–2035 TSMC capacity constraints, ASIC supply chain risks, geopolitical semiconductor exposure & investment implications |
$299 |
5 Things Every Investor Needs to Know About the Custom ASIC Market
1 | ASICs will surpass GPUs in shipment volume by 2028. This is not a projection about the distant future — it is a trajectory already visible in the 2026 deployment plans of Google, Meta, Amazon, and Microsoft. For the semiconductor industry, this marks the most significant architectural shift since GPUs replaced CPUs for AI workloads.
2 | Broadcom is the infrastructure of the ASIC revolution. With 60% projected market share in AI server compute ASIC design partnerships and a 2nm SoC already in production, Broadcom has established a position in the custom ASIC market that would take competitors years to replicate.
3 | The ASIC shift is not killing NVIDIA — it is redefining its market. NVIDIA will continue to dominate flexible AI compute, research workloads, and any application where model architectures are still evolving. The ASIC shift absorbs the marginal GPU demand at the top of the market — the most predictable, highest-volume hyperscaler workloads.
4 | The custom ASIC market has natural barriers to entry. Advanced packaging at 2nm nodes, hybrid bonding technology, and the multi-year design cycles required for competitive ASIC products mean that only a handful of companies can play. Broadcom and Marvell have a structural advantage that will take new entrants a decade to close.
5 | The semiconductor capital equipment market is the next beneficiary. Custom ASIC growth drives demand for advanced EUV lithography (ASML), advanced packaging equipment (Applied Materials, AMAT), and high-bandwidth memory (Micron, SK Hynix). Investors tracking the ASIC market should look beyond chip designers to the equipment and materials companies that enable them.
Conclusion
The custom ASIC market is not a niche disruption. It is the central structural transformation of the AI infrastructure era — one that will define which semiconductor companies capture the most value from the $3.5 trillion AI capital expenditure wave through 2030.
Google, Meta, Amazon, and Microsoft are not abandoning NVIDIA. They are taking ownership of the compute that matters most to them: the high-volume, predictable, mission-critical inference workloads that drive the majority of their AI infrastructure costs. By building custom ASICs, they simultaneously reduce costs, improve performance, and eliminate supply chain dependency on any single vendor.
For investors, the custom ASIC market in 2026 presents a clear thesis: Broadcom as the dominant design partner, Marvell as the credible challenger, TSMC as the indispensable manufacturer, and Micron as the memory supplier that makes it all run. The shift from GPU-centric to ASIC-centric AI infrastructure is not a risk to monitor. It is an opportunity to position for.
| 🔑 The Core Investment Thesis
Custom ASICs will command over 50% of AI accelerator shipments by 2027. Broadcom, with 60% ASIC design market share and 2nm production capability, is the infrastructure company of the ASIC era. The question for investors is not whether this shift will happen — it is whether they are positioned to benefit from it before the market fully prices it in. |
🔗 Read also: GTC 2026 Wrap-Up: 10 Biggest NVIDIA Announcements That Will Define AI in 2027
🔗 Read also: Micron’s $25B Bet: Why AI Memory Is the Next Semiconductor Gold Rush
Frequently Asked Questions
What is a custom ASIC and how is it different from a GPU?
A custom ASIC (Application-Specific Integrated Circuit) is a chip designed to perform one specific task — like running a recommendation model or training a language model — with maximum efficiency. Unlike an NVIDIA GPU, which is engineered for flexibility across any AI workload, a custom ASIC sacrifices flexibility for 3-5x better performance per watt on its target task. At hyperscale volumes, this efficiency difference translates into billions of dollars in annual savings.
Why are hyperscalers like Google, Meta, and Amazon building custom ASICs instead of buying NVIDIA GPUs?
Three reasons drive the shift: cost, control, and supply chain independence. Custom ASICs deliver better price-per-performance for predictable, high-volume workloads. They give hyperscalers full control over their hardware roadmap without dependency on NVIDIA’s product cycle or pricing. And they eliminate the supply chain concentration risk of relying on a single vendor for mission-critical infrastructure. Meta’s engineering leadership specifically cited supply diversity and price insulation as key motivations.
Who are the main players in the custom ASIC market in 2026?
Broadcom holds approximately 60% projected market share in AI server compute ASIC design partnerships — powering Google’s TPU, Meta’s MTIA, Microsoft’s Maia, and OpenAI’s Titan program. Marvell Technology is the primary challenger, with confirmed design wins at Amazon and Microsoft. TSMC is the dominant manufacturer for all advanced ASIC programs. In the networking silicon layer, Broadcom is also the dominant supplier with no credible near-term challenger.
Will custom ASICs replace NVIDIA GPUs?
Not completely — the two serve different needs. Custom ASICs are optimal for fixed, high-volume, predictable workloads at hyperscale. NVIDIA GPUs remain the dominant choice for research, diverse enterprise AI, startups, and any workload where model architectures are still evolving. By 2027, custom ASIC shipments will surpass GPU shipments in volume — but both markets will continue growing, reflecting the bifurcation of AI infrastructure into two distinct segments.
What does the custom ASIC boom mean for semiconductor investors?
The custom ASIC market creates investment opportunities across multiple layers of the semiconductor stack: Broadcom and Marvell as ASIC design partners, TSMC as the advanced node manufacturer, Micron and SK Hynix as HBM memory suppliers, and ASML and Applied Materials as equipment providers enabling advanced packaging. The $604 billion AI accelerator market projected by 2033 will not be captured by NVIDIA alone — understanding where else value accrues is the central question for semiconductor investors.
4 Comments