
By Carter James | Oplexa Insights
May 2026 | 18 Min Read
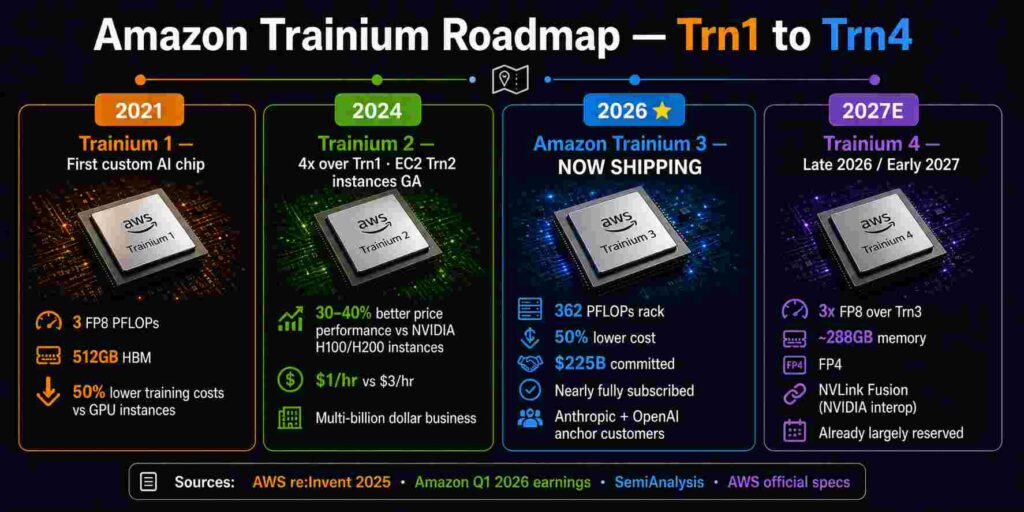
Amazon Trainium 3 is no longer a promising challenger. It is a production-deployed, revenue-generating AI chip business with $225 billion in committed customer revenue — and it is shipping now. AWS CEO Andy Jassy confirmed on Amazon’s Q1 2026 earnings call that Amazon Trainium 3 started shipping in 2026, is 30–40% more price-performant than Trainium 2, and is already nearly fully subscribed. Trainium 4, with specs that match NVIDIA’s Vera Rubin, has already had much of its capacity reserved despite being 18 months from broad availability.
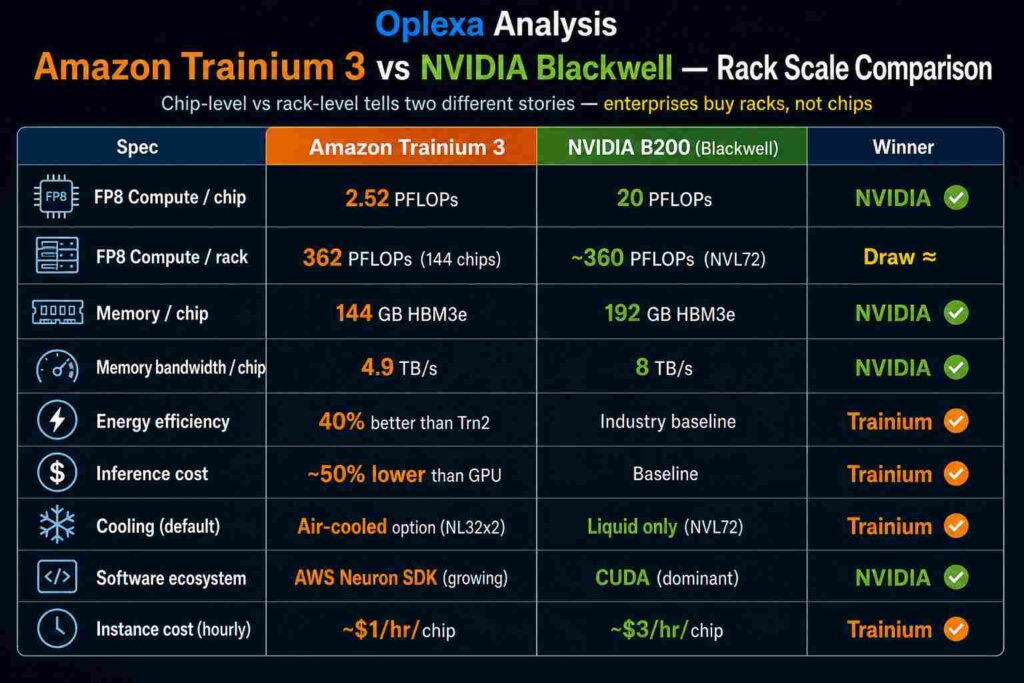
For the first time since NVIDIA established its AI GPU monopoly in 2022, a hyperscaler’s custom silicon is not just cost-competitive — it is at rack-scale performance parity with NVIDIA’s best systems. The Amazon Trainium 3 UltraServer, with 144 chips per rack, delivers 362 MXFP8 PFLOPs — matching NVIDIA’s Blackwell NVL72 — at approximately 50% lower total cost of ownership. That is not a niche alternative. It is a credible primary infrastructure choice for any enterprise running AI on AWS.
This is Oplexa’s complete analysis of Amazon Trainium 3: full technical specifications, rack-level comparison against NVIDIA Blackwell and Google TPU v7, real customer cost data, the Trainium 4 roadmap, and what the $225 billion commitment signals for the AI chip market through 2028.

Amazon Trainium 3 — Full Technical Specifications
Amazon Trainium 3 is AWS’s first 3nm AI accelerator, built on TSMC’s N3P process node — the same advanced node used in Apple’s latest processors and a direct competitor to NVIDIA’s Blackwell architecture at the silicon level. Understanding the technical architecture is essential for evaluating Amazon Trainium 3 against NVIDIA alternatives, because the performance story at chip level and rack level tell very different stories.
Chip-Level Architecture
Amazon Trainium 3 is a dual-chiplet design. Each chip contains two compute chiplets, each with four NeuronCore-v4 cores, connected via a proprietary high-bandwidth interface. Each chip packs:
- Compute: 2.52 PFLOPs MXFP8 per chip — 2x improvement over Trainium 2
- Memory: 144GB HBM3e across four stacks
- Memory bandwidth: 4.9 TB/s — 3.9x over Trainium 2
- Data types: MXFP8, MXFP4, BF16, TF32, FP32
- Process node: TSMC 3nm (N3P)
- Cooling: Both air-cooled (NL32x2) and liquid-cooled (NL72x2) SKUs available
A key innovation in Amazon Trainium 3 is the Logical NeuronCore Configuration (LNC) feature — allowing the Neuron compiler to fuse four physical cores into a wider synchronized logical core with combined compute, SRAM, and HBM. This is particularly valuable for very large AI models with wide layers or long sequence lengths.
Rack-Scale: The Trn3 UltraServer
The Amazon Trainium 3 UltraServer is where the performance story fundamentally changes. By packing 144 chips into a single integrated system, AWS achieves rack-level numbers that directly challenge NVIDIA’s flagship:
- Total compute: 362 MXFP8 PFLOPs per UltraServer
- Total memory: 20.7 TB HBM3e
- Total bandwidth: 706 TB/s
- Interconnect: NeuronSwitch-v1 — 2x bandwidth within the server
- Inter-chip latency: Under 10 microseconds via Neuron Fabric
- Cluster scale: EC2 UltraClusters 3.0 scales to 1 million chips — 10x previous generation
Sources: AWS official specs · Tom’s Hardware Trainium 3 deep dive · SemiAnalysis · NVIDIA product page · Oplexa Analysis
The $225 Billion Signal — Why Amazon Trainium 3 Is Different This Time
Every hyperscaler has announced custom AI chips over the past five years. What makes Amazon Trainium 3 fundamentally different from previous custom silicon announcements — including earlier Trainium generations — is the revenue commitment behind it.
Amazon CEO Andy Jassy confirmed on the Q1 2026 earnings call that Amazon holds more than $225 billion in Trainium revenue commitments. Anchor customers Anthropic and OpenAI have signed on for up to 5 gigawatts and approximately 2 gigawatts of Trainium capacity respectively. Trainium 2 is largely sold out. Amazon Trainium 3 is nearly fully subscribed despite just starting to ship. And Trainium 4 — which is still approximately 18 months from broad availability — has already had much of its capacity reserved.
This demand profile is structurally different from speculative chip announcements. When the two largest AI companies in the world — Anthropic (running Claude) and OpenAI (running ChatGPT) — have committed gigawatts of capacity on Amazon Trainium 3, it validates both the technical credibility and the commercial economics of the platform. These companies run some of the most demanding AI workloads in the world. If Amazon Trainium 3 is good enough for Claude and ChatGPT inference at production scale, it is good enough for the overwhelming majority of enterprise AI workloads.
“Amazon’s chip run rate would be $50 billion if the chip business were a standalone operation.” — Andy Jassy, CEO Amazon, Q1 2026 Earnings Call, April 29, 2026
📊 Oplexa Report: Custom ASIC Market 2026–2033: $118 Billion Opportunity — Full competitive landscape, Amazon Trainium vs Google TPU vs Meta MTIA market share model, hyperscaler custom silicon revenue projections, and 7-year investment thesis. $1,499 →
Amazon Trainium 3 vs Google TPU v7 Ironwood — The Other Custom Chip
The Amazon Trainium 3 story does not exist in isolation. Google’s TPU v7 Ironwood — the current generation inference chip announced at Google Cloud Next 2025 — and the emerging TPU v8 architecture are the primary custom ASIC competitors in the same performance tier. Understanding how Amazon Trainium 3 positions against Google’s silicon is essential for enterprises choosing between AWS and Google Cloud infrastructure.
At pod scale, Google’s TPU v7 Ironwood delivers 42.5 exaflops — a figure that significantly exceeds the Amazon Trainium 3 UltraServer at 362 PFLOPs. However, the comparison is not apples-to-apples: TPU v7 is measured at full pod scale (hundreds of chips), while the Trainium 3 figure is per UltraServer (144 chips). Both systems scale significantly when multiple servers or pods are connected. More importantly, TPU v7 is inference-optimized — it is not the ideal training comparison for Amazon Trainium 3, which is designed for both dense training and inference workloads.
The practical enterprise decision between Amazon Trainium 3 and Google TPU comes down to cloud provider: Trainium is AWS-only, TPU is Google Cloud-only. Enterprises already committed to one cloud ecosystem will generally use that platform’s custom silicon. Multi-cloud enterprises will evaluate both based on workload-specific cost-per-token economics.
Real Customer Data — What Amazon Trainium 3 Actually Costs in Production
Spec sheet comparisons are useful. Production cost data from real customers is more useful. Amazon Trainium 3 has now been running at production scale for several months, and the customer evidence is unambiguous on cost.
Anthropic — Claude Production Inference
Anthropic — the company behind Claude, which hit $30 billion ARR in April 2026 — runs production workloads on Amazon Trainium 3. Anthropic signed up for 5 gigawatts of Trainium capacity, making it the single largest Trainium customer. The fact that an AI safety company running one of the world’s most commercially successful frontier models chose Amazon Trainium 3 for production inference — not just as a cost experiment — is the most credible technical endorsement available in the market.
Decart — 4x Faster Inference at Half the Cost
Decart, which runs real-time generative video workloads, reported that Amazon Trainium 3 delivers 4x faster inference at half the cost compared to GPU alternatives. For video generation — one of the most memory-bandwidth-intensive AI workloads — this result directly validates Trainium 3’s 4.9 TB/s memory bandwidth advantage in practice, not just on paper.
Karakuri, NetoAI, Ricoh, Splash Music
Across AWS’s disclosed customer base on Amazon Trainium 3, the consistent reported metric is 50% lower training and inference costs versus GPU alternatives. This range — across inference-heavy, training-heavy, and mixed workloads — suggests the cost advantage is structural and generalizable, not workload-specific.
The $1 vs $3 Per Hour Reality
At instance level, the pricing gap between Amazon Trainium 3 and NVIDIA GPU instances is stark. NVIDIA H100 chips cost approximately $3 per hour per chip via cloud providers like CoreWeave. Trainium chips are available for roughly $1 per hour — a 3x difference. For enterprises running continuous AI workloads — 24/7 AI agents, always-on inference APIs, large-scale training jobs — this per-hour gap compounds into seven-figure annual savings at meaningful volume.
📊 Oplexa Report: AI Infrastructure Strategy 2026–2035: Capital & Compute — Full cost-per-token comparison across Trainium 3, NVIDIA Blackwell, and Google TPU v7/v8, enterprise cloud workload framework, and build vs buy analysis. $999 →
The AWS Neuron SDK — The CUDA Problem and How Amazon Is Solving It
The single biggest obstacle to Amazon Trainium 3 adoption is not the hardware. It is the software. NVIDIA’s CUDA platform has a 15-year head start and a developer ecosystem of millions of engineers who have built their AI frameworks, tools, and workflows on CUDA-native toolchains. Switching to Amazon Trainium 3 means migrating to the AWS Neuron SDK — a meaningful engineering investment.
AWS has internalized this barrier and is pursuing the same strategy that made CUDA dominant: open-source the developer tools and build the ecosystem. Key developments in 2026:
- PyTorch native integration: Developers can train and deploy on Amazon Trainium 3 by changing a few lines of configuration in existing PyTorch code — no framework rewrite required
- Hugging Face, vLLM, PyTorch Lightning support: Neuron SDK now integrates with the most widely used AI libraries
- Amazon SageMaker integration: Trn3 instances spin up as easily as GPU instances — no bare metal management
- LNC=8 support coming mid-2026: The Logical NeuronCore configuration most ML research scientists prefer — currently limited to LNC=1 and LNC=2 — will be broadly available mid-2026, removing a key barrier for wider research adoption
- Open source stack: AWS has open-sourced most of its software stack to broaden adoption and kick-start a developer community around Trainium
The CUDA moat is not constructed by NVIDIA engineers alone — it is constructed by millions of external developers. AWS is pursuing the exact same strategy for Neuron SDK, understanding that community contribution compounds over time.
Amazon Trainium 4 — The Roadmap That Changes the Game for 2027
The Amazon Trainium 3 announcement at re:Invent 2025 included a preview of Trainium 4 that carries strategic significance beyond the specs. Trainium 4 targets late 2026 or early 2027 availability with:
- Performance: At least 3x the FP8 processing power of Trainium 3 — bringing it into Vera Rubin GPU territory
- Memory: 2x capacity at approximately 288GB — identical to NVIDIA Vera Rubin’s spec
- Bandwidth: 4x improvement over Trainium 3
- Data types: Native FP4 support — matching NVIDIA’s Vera Rubin and Google’s TPU v8
- NVLink Fusion support: Trainium 4 will support NVIDIA’s NVLink Fusion interconnect, enabling heterogeneous clusters combining Trainium XPUs with NVIDIA GPUs and AWS Graviton CPUs in common racks
The NVLink Fusion support is the most strategically significant element of the Trainium 4 roadmap. It signals a deliberate détente: AWS will compete with NVIDIA on accelerators while integrating NVIDIA’s connectivity standards. Enterprises can build hybrid clusters combining Amazon Trainium chips for cost-optimized inference with NVIDIA GPUs for frontier model training — using a single rack infrastructure standard. This cross-compatibility is the single biggest barrier removal for CUDA-native enterprises considering Trainium adoption.
Investment Signals — What Amazon Trainium 3 Means for Semiconductor Investors
The Amazon Trainium 3 story carries four distinct investment signals for institutional investors and enterprise strategists.
Signal 1 — Amazon’s Chip Business Is Scaling to $50 Billion ARR
Amazon’s chip business — Graviton CPUs, Trainium AI accelerators, and Nitro networking chips — exited Q1 2026 at a $20 billion annual run rate with nearly 40% sequential growth. CEO Andy Jassy noted the run rate would be $50 billion if presented as a standalone company. That trajectory — combined with $225 billion in Trainium revenue commitments — positions Amazon as the second-largest AI chip business in the world by committed revenue, behind only NVIDIA. For semiconductor investors, Amazon is a major chip revenue story embedded inside an e-commerce and cloud narrative that most equity analysts undervalue.
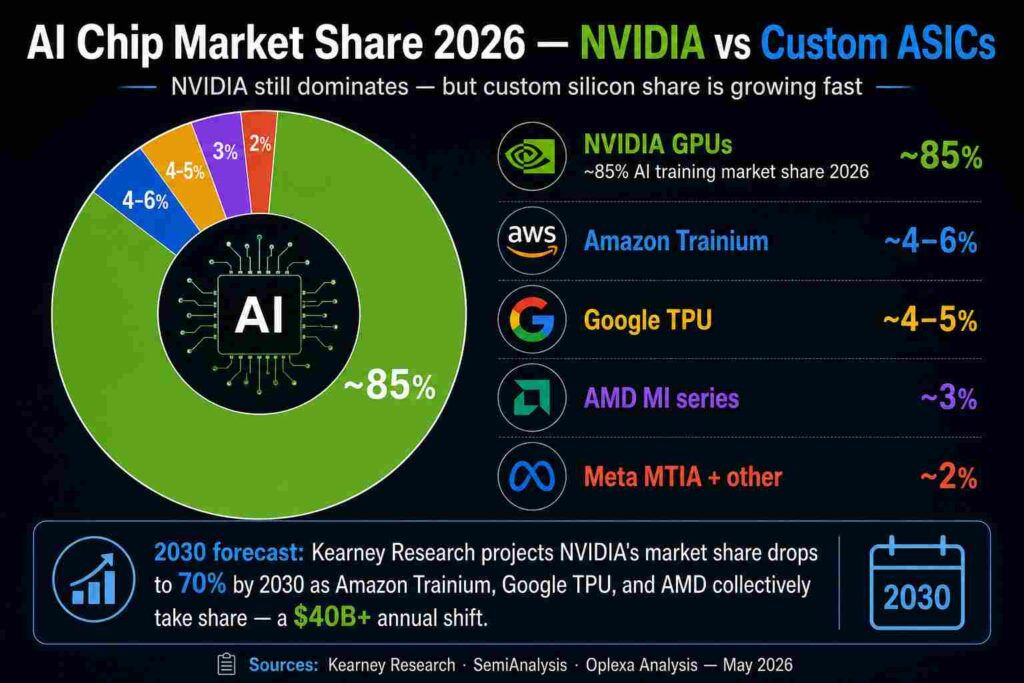
Signal 2 — NVIDIA Faces Real Pricing Pressure for the First Time
The emergence of Amazon Trainium 3 at rack-scale parity with Blackwell pricing at 50% lower cost is the first credible challenge to NVIDIA’s pricing power in AI infrastructure. Combined with Google’s TPU v8, Meta’s MTIA 2 gigawatt deployment, and AMD’s MI300X wins at Azure and Meta, NVIDIA now faces meaningful at-scale alternatives for the first time. Kearney Research projects NVIDIA’s AI chip market share declines from 85% to 70% by 2030 — a $40B+ annual revenue shift to custom ASIC platforms.
Signal 3 — TSMC Wins Regardless
Amazon Trainium 3 is built on TSMC’s 3nm N3P node. NVIDIA Vera Rubin is on TSMC 3nm. Google TPU v8 Zebrafish is on TSMC 3nm. Every major AI chip generation in 2026 runs on TSMC’s most advanced nodes. As covered in our TSMC $7 trillion investment analysis, TSMC is the only foundry capable of manufacturing all of these chips simultaneously. The custom ASIC competition is TSMC’s revenue regardless of who wins market share.
Signal 4 — Broadcom’s Position Is Evolving
Broadcom designs Google’s TPU v8 Sunfish and co-designed Meta’s MTIA chips. But Amazon Trainium 3 is designed entirely in-house at AWS’s Annapurna Labs — no Broadcom involvement. As Amazon’s custom silicon business scales, it represents revenue that flows to AWS engineers rather than Broadcom. For investors holding Broadcom on the custom ASIC thesis, this is worth monitoring. The covered analysis in our Broadcom-Google TPU deal analysis provides the competitive context.
Should Your Enterprise Use Amazon Trainium 3 or NVIDIA GPUs in 2026?
The Amazon Trainium 3 decision is not binary. Here is the practical framework for enterprise infrastructure teams:
Choose Amazon Trainium 3 If:
- Your primary AI workloads run on AWS and you are cost-sensitive on inference at scale
- You run PyTorch-native models — Neuron SDK integration requires minimal code changes
- Your workloads are inference-heavy — chatbots, recommendation systems, AI agents — where 50% cost reduction compounds at high volume
- You are Anthropic’s Claude API customer or run Llama 4 variants — both are production-validated on Trainium 3
- Your facility cannot support liquid cooling — Trainium 3’s air-cooled NL32x2 SKU gives deployment flexibility NVIDIA Vera Rubin cannot match
Stick With NVIDIA If:
- Your team is CUDA-dependent with significant framework investment that cannot be migrated without major engineering effort
- You need Trainium 3’s LNC=8 support — currently limited until mid-2026
- You are a frontier model researcher requiring the highest absolute peak training throughput
- You are multi-cloud or not committed to AWS — Trainium only runs on AWS
- You require the broadest model and framework compatibility that only CUDA provides today
Conclusion
Amazon Trainium 3 represents a structural shift, not just a product announcement. A hyperscaler’s custom AI chip has achieved rack-scale performance parity with NVIDIA’s best system at half the cost — with $225 billion in committed revenue proving that the world’s most demanding AI workloads trust it in production. That combination has never existed before in the history of AI chip competition.
NVIDIA is not losing its dominant position in 2026. Its CUDA ecosystem, software stack, and three-generation roadmap visibility remain formidable competitive advantages that Amazon Trainium 3 cannot match today. But the economics of AI infrastructure have permanently changed. Enterprises now have a credible, production-validated alternative for high-volume inference and training on AWS. Frontier AI companies like Anthropic and OpenAI are running their most important workloads on Amazon Trainium 3. And Trainium 4 — with NVLink Fusion support — will make hybrid Trainium-NVIDIA deployments practical for CUDA-native enterprises by early 2027.
The NVIDIA monopoly on AI chip pricing is over. Amazon Trainium 3 is the most concrete evidence yet that the custom ASIC era of AI infrastructure has arrived.
📊 Oplexa Report: NVIDIA Strategic Inflection Analysis 2025–2035 — Full competitive threat model from Amazon Trainium, Google TPU, and custom ASICs, NVIDIA market share projections by year, Vera Rubin revenue scenarios, and 10-year institutional investment thesis. $2,500 →
Frequently Asked Questions
What is Amazon Trainium 3?
Amazon Trainium 3 is AWS’s third-generation custom AI accelerator, built on TSMC’s 3nm process. Each chip delivers 2.52 PFLOPs MXFP8 with 144GB HBM3e and 4.9 TB/s memory bandwidth. In Trn3 UltraServer configuration with 144 chips it delivers 362 PFLOPs — matching NVIDIA Blackwell NVL72 at rack scale — while costing 50% less than comparable GPU alternatives. It went into general availability in March 2026.
How does Amazon Trainium 3 compare to NVIDIA Blackwell?
At chip level, NVIDIA B200 outperforms Trainium 3 at 20 PFLOPs versus 2.52 PFLOPs. At rack scale, the Trainium 3 UltraServer (144 chips, 362 PFLOPs) matches Blackwell NVL72 (~360 PFLOPs) at approximately 50% lower cost per workload. Trainium 3 also delivers 40% better energy efficiency. NVIDIA retains the advantage in software ecosystem breadth (CUDA) and absolute peak single-chip performance.
How much does Amazon Trainium 3 cost?
Amazon Trainium 3 instance pricing is approximately $1 per chip per hour versus $3 per chip per hour for NVIDIA H100 GPU instances — a 3x pricing difference. At workload level, customers including Anthropic, Decart, and Karakuri report 50% lower training and inference costs versus GPU alternatives. For inference, Decart reported 4x faster inference at half the cost using Trainium 3 for real-time generative video.
What is Amazon Trainium 4?
Amazon Trainium 4 is the next-generation chip targeting late 2026 or early 2027. It promises 3x FP8 performance, 4x memory bandwidth, ~288GB memory, native FP4 support, and — most significantly — NVIDIA NVLink Fusion support for hybrid Trainium-NVIDIA GPU clusters. Much of Trainium 4’s capacity has already been reserved, despite it being 18 months from broad availability.
Should enterprises switch from NVIDIA to Amazon Trainium 3?
Not entirely, but enterprises running high-volume inference or training on AWS should seriously evaluate Amazon Trainium 3. Production deployments at Anthropic and OpenAI validate the 50% cost reduction. PyTorch-native workloads require minimal migration effort. The right approach for most enterprises is a hybrid strategy — Trainium 3 for cost-sensitive inference at scale, NVIDIA for frontier model training and CUDA-dependent workloads — until Trainium 4’s NVLink Fusion support arrives in early 2027.
Is Amazon Trainium 3 better than Google TPU?
Amazon Trainium 3 and Google TPU v7 Ironwood are not directly comparable — they are custom chips designed for their respective cloud platforms. Trainium 3 is AWS-only, TPU is Google Cloud-only. At rack scale, both achieve similar performance tiers but with different memory architectures and software ecosystems. Enterprises already on AWS should evaluate Trainium 3; enterprises on Google Cloud should evaluate TPU v7/v8. Multi-cloud enterprises should run cost-per-token analysis for their specific workloads on both platforms.
Related Oplexa Coverage:
- Custom ASIC Market 2026: Why Hyperscalers Are Ditching NVIDIA — The broader competitive context Amazon Trainium 3 is part of
- NVIDIA $5 Trillion Market Cap: What Happens Next — How Amazon Trainium 3 affects NVIDIA’s valuation thesis
- NVIDIA Vera Rubin GPU: Complete Platform Guide — The NVIDIA system Trainium 3 is competing with at rack scale
- Google Cloud Next 2026: TPU v8 and the Google ASIC Strategy — The other hyperscaler custom chip competing with Trainium
- AI Data Center Power Crisis 2026 — Why Trainium 3’s 40% energy efficiency advantage matters structurally
- DeepSeek V4 vs GPT-5.5: The Inference Cost War — How model-level economics interact with chip-level cost advantages
- TSMC: The $7 Trillion AI Investment — TSMC as the foundry behind both Trainium 3 and NVIDIA Vera Rubin
📊 Oplexa Report: Custom ASIC Market 2026–2033 — $1,499
Amazon Trainium vs Google TPU vs Meta MTIA competitive analysis, hyperscaler custom silicon market share projections, NVIDIA displacement model, and 7-year investment thesis for the $118B ASIC opportunity.
📊 Oplexa Report: AI Infrastructure Strategy 2026–2035 — $999
Cost-per-token comparison across Trainium 3, NVIDIA Blackwell/Vera Rubin, and Google TPU v7/v8. Enterprise cloud workload framework, build vs buy analysis, and 10-year capex allocation model.
📊 Oplexa Report: NVIDIA Strategic Inflection Analysis 2025–2035 — $2,500
Full competitive threat model from Trainium, TPU, and custom ASICs. NVIDIA market share scenarios by year, Vera Rubin revenue model under custom ASIC pressure, and 10-year institutional investment framework.